INTRODUCTION
Imagine you are standing in a pitch-black room with a thousand switches on the wall. You are told that one specific combination of these switches will play a perfect symphony, while every other combination will produce nothing but ear-splitting static.
You have no map. You have no instructions. You can only flip a switch, listen to the noise, and try to guess if the sound got slightly better or slightly worse.
This is the terrifying, beautiful, and chaotic reality of a Neural Network on its first day of training.
Every second, we interact with these digital “brains.” They recognize our faces to unlock our phones, translate languages in real-time, and generate art that looks like it was painted by a human master. We treat it like magic. We call it “Artificial Intelligence” and speak as if the software is actually thinking.
But if you were to peel back the sleek interface of ChatGPT or Midjourney, you wouldn’t find a conscious mind. You wouldn’t even find a set of logical “If-Then” rules like the software of old. Instead, you would find a vast, dizzying landscape of mathematics, a symphony of billions of tiny numbers, constantly shifting, vibrating, and correcting themselves.
The mystery isn’t that we’ve built a machine that can talk; it’s that we’ve built a machine that can learn.
For decades, we tried to “teach” computers by giving them rigid instructions. We told them: “If an object has two pointed ears and whiskers, it is a cat.” But the computer would fail the moment it saw a cat from behind or a cat with its ears tucked back. We were trying to program the world, but the world was too messy to be programmed.
So, we changed our approach. We stopped giving the computer rules and started giving it examples. We built a digital structure inspired by the human brain, a neural network and told it: “Here are ten million photos. Figure it out yourself.”
In this investigative deep-dive, we are going to demystify the “Black Box.” We will explore how a pile of math transforms into a recognition engine, how “Backpropagation” allows a machine to learn from its own failures, and why the future of our civilization now rests on a process of trial and error at a trillion-scale.
Welcome to the heart of the machine.
TABLE OF CONTENTS
- The Architecture: A Stadium of People Passing Notes
- The Anatomy: Neurons, Layers, and the Invisible Connections
- The “Volume Knobs”: Understanding Weights and Biases
- Forward Propagation: The First (Usually Terrible) Guess
- The Cost Function: Measuring the Failure
- Backpropagation: Tracing the Blame
- Gradient Descent: The Mountain in the Fog
- Activation Functions: The Spark of Nonlinearity
- Common Myths About AI Learning
- The Future of Neural Learning
- FAQs
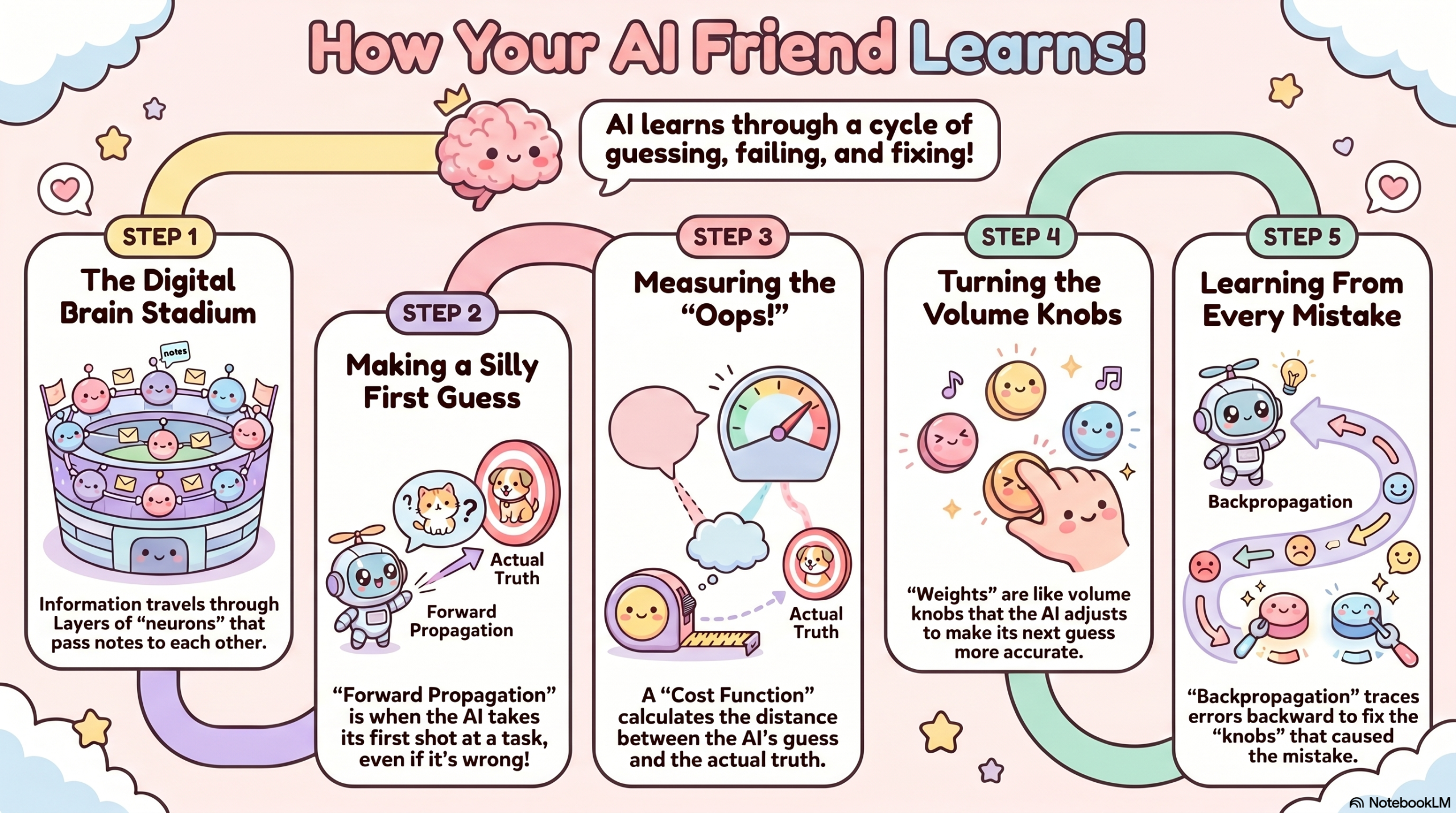
The Architecture: A Stadium of People Passing Notes
To understand a neural network without looking at code, imagine a massive stadium filled with 100,000 people. Each person represents a neuron.
These people are organized into vertical rows (Layers).
- The First Row (Input Layer): They are looking at a giant screen showing a blurry image of a handwritten number “7.”
- The Middle Rows (Hidden Layers): They can’t see the screen. They can only receive notes from the row behind them, do a tiny bit of math, and pass a new note to the row in front of them.
- The Last Row (Output Layer): There are only 10 people here, labeled 0 through 9. Their job is to shout when they receive a signal.
At the very beginning, the people are passing notes randomly. The note might say: “I saw a horizontal line, so I’m sending a ‘5’ to the next guy.” By the time the message reaches the front, the person labeled “3” shouts.
But the image was a “7.” The network was wrong.
The “learning” happens when a supervisor walks onto the field and says: “You were wrong. It was a 7. Everyone who contributed to the ‘3’ guess needs to change their behavior, and everyone who noticed features of a ‘7’ needs to be louder next time.”
The Anatomy: Neurons, Layers, and the Invisible Connections
In biological terms, your brain uses neurons and synapses. In digital terms, a neural network uses nodes and edges.
The Input Layer: Sensory Perception
Everything starts here. If you feed an AI an image, it doesn’t “see” a picture; it sees a grid of pixels. Each pixel has a numerical value representing its brightness ($0 for black, $255 for white). These numbers are the “Input.”
The Hidden Layers: The Detectors
This is where the magic happens. The first hidden layer might look for simple shapes, edges, corners, or vertical lines. The second layer combines those lines into shapes like circles or squares. The third layer combines those shapes into “features” like eyes, ears, or wheels.
The deeper the network, the more complex the features it can recognize. This is why we call it Deep Learning.
The Output Layer: The Decision
The final layer produces the result. It’s usually a list of probabilities. It doesn’t say: “This is a dog.” It says: “I am 92% sure this is a dog, 7% sure it’s a cat, and 1% sure it’s a blueberry muffin.”
The “Volume Knobs”: Understanding Weights and Biases
If neurons are the people in the stadium, Weights are the volume of their voices.
Each connection between neurons has a “Weight.” Think of it as a volume knob.
- A High Weight means: “This information is very important! Pay attention!”
- A Low Weight (or zero) means: “Ignore this. It’s just noise.”
There is also something called a Bias. Think of the Bias as a “threshold for excitement.” Some neurons are very stubborn; they won’t pass a message unless the input is incredibly strong. Others are very “excitable” and will pass a message at the slightest hint of data.
When we say an AI is “learning,” we mean the computer is turning billions of these tiny “Volume Knobs” (Weights and Biases) until the math works out perfectly.
The Math Layer: Every neuron performs a calculation:
Forward Propagation: The First (Usually Terrible) Guess
The first time a neural network tries to perform a task, it is essentially a baby throwing darts in the dark. This process is called Forward Propagation.
- Data enters the input layer.
- The math ripples through the hidden layers, multiplied by random weights.
- An output is generated.
Because the weights were random, the output is almost certainly garbage. If you ask it to identify a bird, it might tell you it’s a toaster. But this failure is essential. You cannot have a correction without an error.
The Cost Function: Measuring the Failure
How do you tell a computer how wrong it is? You use a Cost Function (also called a Loss Function).
Imagine you are practicing archery. If you hit the bullseye, your “Cost” is zero. If you miss the target entirely and hit a nearby tree, your “Cost” is very high.
The Cost Function calculates the mathematical distance between the AI’s Guess and the Actual Truth.
- The Goal of AI Training: To get the Cost Function as close to zero as possible.
Backpropagation: Tracing the Blame
This is the most important concept in all of modern Artificial Intelligence. If Forward Propagation is the “Guess,” Backpropagation is the “Learning.”
Once the Cost Function determines that the AI was wrong, the network does something brilliant: It works backward.
It goes to the Output Layer and asks: “Which neurons caused this mistake?”
Then it goes to the Hidden Layers and says: “You passed a strong signal to the wrong guy. We are going to lower your weight.”
It traces the “blame” for the error all the way back to the beginning, adjusting every single volume knob (Weight) a tiny bit to ensure the error is smaller next time.
Gradient Descent: The Mountain in the Fog
If you have a billion knobs to turn, how do you know which way to turn them? Do you turn them up or down? And by how much?
Engineers use a strategy called Gradient Descent.
Imagine you are standing on top of a mountain (The Mountain of High Error) and you are surrounded by thick fog. You want to get to the valley at the bottom (The Valley of Zero Error), but you can’t see the path.
What do you do?
You feel the ground with your feet. You find the direction that slopes downward the most, and you take one small step in that direction. Then you feel the ground again. You take another step.
Eventually, by always moving “downhill,” you will reach the bottom.
- The Slope: This is the “Gradient.”
- The Step: This is the “Learning Rate.” (If your steps are too big, you might jump over the valley. If they are too small, it will take a million years to get there).
Activation Functions: The Spark of Nonlinearity
There is one more secret ingredient. If all a neural network did was multiply inputs by weights, it would just be a giant, flat calculator. It wouldn’t be able to handle complex patterns.
To solve this, each neuron has an Activation Function. This is a mathematical gatekeeper that decides whether a neuron should “fire” or stay silent.
The most popular one is called ReLU (Rectified Linear Unit). Its rule is simple: “If the number is negative, turn it to zero. If it’s positive, keep it as it is.”
This tiny bit of logic allows the network to learn “Nonlinear” relationships, the complex, curvy, and unpredictable patterns that make up the real world.
Common Myths About AI Learning
Myth 1: AI “Thinks” Like a Human
While the structure is inspired by the brain, the process is entirely different. Your brain doesn’t perform multi-billion-parameter matrix multiplication to decide if you want coffee. AI is a mathematical mimic; it finds patterns, but it doesn’t “understand” them.
Myth 2: Neural Networks Are Always Right
Neural networks are only as good as their data. If you train a network to recognize “Healthy People” but only show it photos of people in the sun, the network might “learn” that sunshine is the cause of health. This is called Overfitting, and it’s one of the biggest challenges in AI.
Myth 3: We Know Exactly How They Work
We understand the math of how they learn, but for very large networks (like GPT-4), we don’t always know why a specific neuron decided to focus on a specific feature. This is known as the “Interpretability Problem.”
The Future of Neural Learning
We are entering a new era of AI where the goal isn’t just “more data,” but “better thinking.”
- Neuromorphic Computing: Designing physical computer chips that act like biological neurons, using 1,000x less power.
- Few-Shot Learning: Teaching AI to learn from just two or three examples, just like a human child, rather than needing ten million photos.
- Self-Supervised Learning: Allowing AI to explore the world and “label” its own data without human help.
FAQ SECTION
1. Can a neural network learn without a human?
Yes, in a process called Unsupervised Learning. The network looks for patterns in data without being told what the “truth” is. For example, it might cluster customers into groups based on buying habits without being told what those groups represent.
2. How many layers are in a “Deep” neural network?
It varies. Simple networks might have 3-5 layers. Modern “Deep” models like those used for self-driving cars or language generation can have hundreds or even thousands of layers.
3. What is a “Parameter”?
A parameter is just the sum of all the Weights and Biases in a network. When you hear that a model has “175 Billion Parameters,” it means there are 175 billion “volume knobs” that were adjusted during training.
4. Why is a GPU better for AI than a CPU?
A CPU is like a genius who can solve one hard problem at a time. A GPU is like a thousand mediocre mathematicians who can all solve simple multiplications at the exact same time. Since neural networks are just millions of simple multiplications, the GPU is much faster.
5. What happens if the data is biased?
The network will learn the bias. If a hiring AI is trained on data where only men were hired in the past, the “math” will conclude that being male is a “High Weight” feature for success, leading to automated discrimination.
6. Can a neural network “forget”?
Yes. This is called Catastrophic Forgetting. When a network is trained on a new task, it can sometimes overwrite the weights it used for an old task, losing its previous abilities.
7. Is a neural network a program?
Not in the traditional sense. A traditional program is a list of “Rules.” A neural network is a “Weight Map.” You don’t write the code for the logic; the math generates the logic through training.
8. How do you know when to stop training?
Engineers watch the Cost Function. When the error stops going down, or if the network starts “memorizing” the training data (Overfitting) rather than learning patterns, the training is halted.
9. Can neural networks do math?
Surprisingly, they struggle with pure math. They are “Probability Engines,” not “Logic Engines.” They might “predict” that $543 + 212 = 755$ because they’ve seen similar patterns, but they aren’t actually adding the numbers the way a calculator does.
10. Why is “Data” called the “New Oil”?
Because a neural network is just an empty engine without it. The data is the fuel that allows the Backpropagation process to turn random noise into intelligence.
OTHER USEFUL BLOG SUGGESTIONS
- How AI Image Generators Work: The Science of Digital Dreams
- How Recommendation Algorithms Work: The Science of Your Feed
- How Does ChatGPT Work? The Simple Science of AI Answers
CONCLUSION
The story of neural networks is the story of humanity learning to step aside.
For sixty years, we tried to build “intelligent” machines by forcing them to think like we do in rigid lines of code and perfect logic. It didn’t work. The breakthrough only happened when we admitted that the world is too complex for us to explain.
We built the stadium, we recruited the neurons, and we gave them the “Volume Knobs.” Then, we let the math take over.
Neural networks don’t “think” in the way we do, but they have mastered the art of the Correction. They are the ultimate students, failing billions of times a second until they find the signal in the noise.
As we move forward, these networks will only get deeper, faster, and more integrated into our lives. But remember: beneath the talking bots and the beautiful art, it’s just a mountain in the fog, a cost function, and a trillion tiny steps toward the truth.
The machine isn’t waking up. We are just finally learning how to let it learn.