Imagine you are standing in front of a canvas that is currently nothing but static. It looks like a television from 1992 that’s lost its signal a chaotic, vibrating soup of gray and white pixels.
Then, you whisper a sentence: “A Victorian cat wearing a space suit, walking on the surface of Mars, cinematic lighting.”
As soon as the words leave your lips, the static begins to move. It’s subtle at first. A faint orange hue emerges in the bottom third. A rounded shape appears in the center. Within seconds, the chaos resolves. The noise is scrubbed away by an invisible hand. Suddenly, there he is: a ginger tabby in a brass-helmeted pressurized suit, his paws kicking up the red dust of the Valles Marineris.
This isn’t a search engine finding a photo that already exists. It’s not a digital collage of existing images stitched together like a ransom note. This is an entirely new creation, a “dream” constructed from trillions of mathematical probabilities.
We are currently living through the greatest shift in visual communication since the invention of the camera. Tools like Midjourney, DALL-E 3, and Stable Diffusion have turned everyone with a keyboard into a master illustrator. But for most users, the process is a complete “black box.” We type a prompt, wait ten seconds, and magic happens.
But here’s the shocking truth: AI image generators don’t actually know what a “cat” is. They don’t know what “Mars” looks like. And they definitely don’t have a “library” of images stored inside them.
Instead, these models have learned to see the world as a series of patterns in a high-dimensional mathematical landscape. They have learned to find order in total chaos. To understand how they work is to understand one of the most elegant engineering feats in human history.
In this investigative dive, we are going to peel back the pixels. We’ll explore the “Latent Space” where these images are born, the “Diffusion” process that carves art out of noise, and the “CLIP” model that acts as a translator between human language and digital color.
Prepare to see your screen in a way you never have before. Let’s decode the digital ghost in the machine.
TABLE OF CONTENTS
- The “Polaroid in the Fog” Analogy
- The Two Minds: How AI Learns to Connect Words and Pictures
- Step-by-Step: The Journey from Noise to Masterpiece
- The Latent Space: Mapping the Universe of All Possible Images
- Diffusion: Carving Art Out of Static
- Why Do AI Images Have “Hallucinations” (and Extra Fingers)?
- The Advanced Layer: U-Nets, VAEs, and Checkpoints
- Common Myths About AI Art Debunked
- The Future: Video, 3D, and the Ethics of Creation
- Interesting Facts About AI Generation
- FAQs
- Conclusion
The “Polaroid in the Fog” Analogy
To understand AI image generation, you have to stop thinking of the AI as an “editor” and start thinking of it as a “sculptor.”
Imagine you are in a room filled with a thick, impenetrable fog. You can’t see an inch in front of your face. But you know that somewhere inside that fog is a beautiful statue. Your job is to wave your hands and slowly push the fog away until the statue is revealed.
AI image generators do exactly this, but they do it with math.
When you give an AI a prompt, it starts with a “block” of total digital noise (the fog). It then looks at your prompt and says, “Okay, based on everything I’ve learned, if I move these few gray pixels to the left and turn that one slightly blue, it will look 1% more like a ‘cat on Mars’ than it did before.”
It does this over and over, 30, 50, or 100 times. Each time, the image becomes clearer, the “fog” lifts, and eventually, you are left with a high-resolution photo.
The Two Minds: How AI Learns to Connect Words and Pictures
Before an AI can create a “cat,” it has to understand what the word “cat” means in relation to pixels. It does this through a training phase that involves looking at billions of images and their captions.
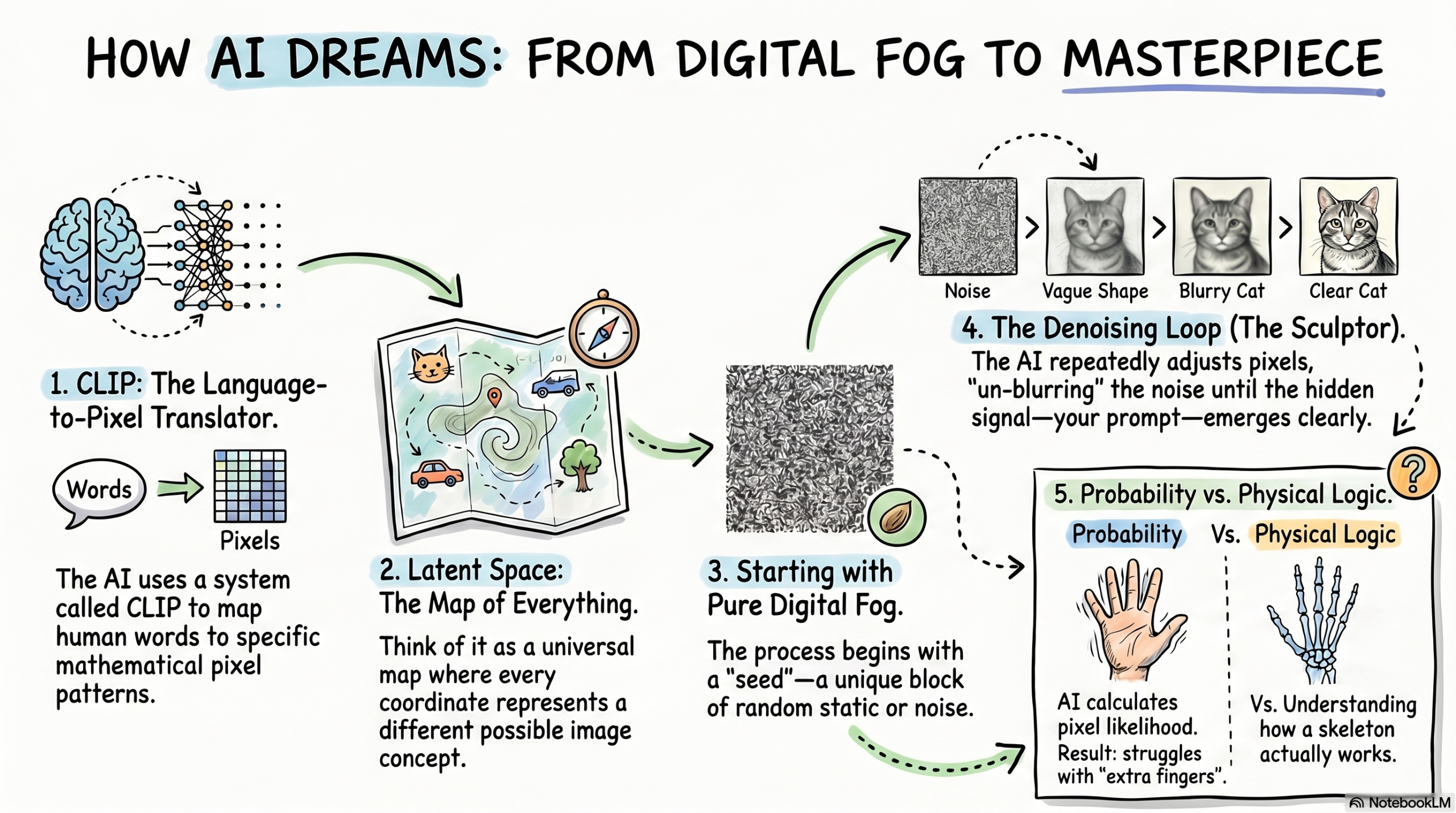
It uses a system called CLIP (Contrastive Language-Image Pre-training). Think of CLIP as the ultimate translator.
- The Image Encoder: One part of the AI looks at a photo of a dog and turns it into a long string of numbers (a “vector”).
- The Text Encoder: Another part looks at the caption “A golden retriever running in a park” and turns that into a string of numbers.
- The Matching Game: The AI is rewarded when the “number strings” for the image and the text are close together in its mathematical “map.”
After billions of repetitions, the AI learns that the mathematical representation of the word “sunset” always appears near pixels that are orange, red, and yellow. It doesn’t “know” what a sunset is; it just knows that when the “sunset” label is present, certain pixel patterns are statistically likely to follow.
Step-by-Step: The Journey from Noise to Masterpiece
How does a prompt actually become an image? Let’s follow a single request: “A cyberpunk city in the rain.”
- Step 1: Tokenization. The AI breaks your prompt into “tokens” (chunks of words). “Cyberpunk” gets its own mathematical code; “City” gets another.
- Step 2: Entering Latent Space. The AI doesn’t work on the full-sized image yet. That would take too much computer power. Instead, it goes into a “compressed” version of the world called Latent Space.
- Step 3: The Initial Noise. The AI generates a random “seed”—a unique pattern of static. This is why you get a different image every time, even with the same prompt.
- Step 4: The Denoising Loop. The AI looks at the static and your “cyberpunk” code. It asks: “Which pixels should I change to make this look more like neon lights and wet pavement?” It adjusts the pixels slightly.
- Step 5: Refinement. It repeats this loop. The neon signs start to glow. The rain streaks appear. The “noise” is slowly traded for “information.”
- Step 6: Upscaling. Finally, the AI takes that compressed “latent” image and “uncompresses” it into the high-resolution photo you see on your screen.
The Latent Space: Mapping the Universe of All Possible Images
This is the most “sci-fi” part of the technology. Imagine a 3D map so large it fills the entire universe. Every single point on that map represents a different possible image.
One corner of the map contains all images of “Victorian houses.” Another corner contains “outer space.” If you move your finger from the “house” corner toward the “space” corner, you will find a middle point that represents a Victorian house on the moon.
This mathematical map is Latent Space.
When you type a prompt, you are essentially giving the AI a set of GPS coordinates. You are saying, “Go to the spot in your memory where ‘Van Gogh’s style’ meets ‘Cyberpunk cities’ and show me what’s there.”
Because the space between these points is continuous, the AI can create things that have never existed before like a “Darth Vader teapot” by simply finding the mathematical midpoint between those two concepts.
Diffusion: Carving Art Out of Static
The core technology behind DALL-E and Midjourney is called Stable Diffusion.
Think of it as two separate processes:
- Forward Diffusion (The Training): Scientists take a clear photo of a tree and slowly add “noise” (static) to it until it’s unrecognizable. The AI watches this happen in reverse, learning exactly how the noise destroyed the tree.
- Reverse Diffusion (The Generation): This is what happens when you use the tool. The AI starts with pure noise and uses everything it learned in the training phase to “undo” the damage, effectively “healing” the static back into a tree.
It is essentially a master of “un-blurring.” It has seen so much noise that it has become an expert at finding the hidden signals buried within it.
Why Do AI Images Have “Hallucinations” (and Extra Fingers)?
We’ve all seen it: a beautiful AI-generated woman with seven fingers, or a dog with two tails. Why is the AI so “smart” at lighting but so “dumb” at anatomy?
The answer lies in statistics.
The AI doesn’t have a 3D model of a human hand in its head. It doesn’t know that a hand has a skeletal structure with five digits. Instead, it has seen millions of photos of hands.
In those photos, hands are often holding things, tucked in pockets, or gesturing at angles where only three fingers are visible. The AI learns that “In the ‘hand’ region of a photo, there is usually a cluster of fleshy cylinders.”
Because it’s playing a game of probability, it sometimes thinks, “Well, based on these pixels, adding one more fleshy cylinder here seems statistically likely!” It is a master of textures and colors, but it struggles with “logical constraints”, the rules of the physical world that aren’t captured by pure pixel probability.
The Advanced Layer: U-Nets, VAEs, and Checkpoints
For the tech enthusiasts, let’s look at the three main components that make this work:
- The VAE (Variational Autoencoder): This is the “compressor.” It shrinks the huge image into the tiny “Latent Space” so the computer doesn’t catch fire trying to process it.
- The U-Net: This is the “engine.” It’s a specific type of neural network shaped like a “U” that is designed to look at an image, identify the noise, and decide how to remove it.
- The Checkpoint: This is the “brain.” When you download a “model” (like Stable Diffusion v1.5 or SDXL), you are downloading a “Checkpoint.” This is the saved file of everything the AI learned during its months of training.
Common Myths About AI Art Debunked
Myth 1: AI art is just a “Google Image Search” collage. False. The AI doesn’t “copy and paste” anything. There are no images stored inside the AI model. If you tried to store the billions of images it was trained on, the file would be petabytes in size. Instead, the AI model is only a few gigabytes, it only stores the mathematical rules it learned about how pixels relate to each other.
Myth 2: AI is “thinking” creatively. False. The AI has no intent. It doesn’t feel inspired. It is a very sophisticated calculator. It is simply calculating the most likely color for a pixel based on the mathematical weight of your words.
Myth 3: AI can’t create original art. Philosophically Complex. While the AI is based on existing data, the specific combination of pixels it generates for your prompt has never existed in the history of the universe. It is “original” in the same way a new song is original even though it uses the same seven notes as every other song.
The Future: Video, 3D, and the Ethics of Creation
We are moving past static images.
- Text-to-Video: Tools like Sora and Veo are applying the “Diffusion” process to time. Instead of generating one image, they are generating 24 “noisy” frames per second and ensuring they are mathematically consistent with each other.
- 3D Generation: AI is learning to generate 3D meshes (the “skeletons” of video game objects) directly from text.
- The Ethical Crisis: Because these models were trained on the work of human artists without their explicit consent, the industry is currently facing massive lawsuits. The future of AI art will likely involve “Ethical Models” trained only on licensed or public-domain data.
Interesting Facts About AI Generation
- The “Fruit Bowl” Problem: Early AI struggled to draw a bowl of fruit because it would often blend the fruits together, creating “App-nanas”, a hybrid of an apple and a banana.
- GPU Power: Generating a single high-quality AI image uses roughly as much electricity as charging your smartphone to 50%.
- Hidden Watermarks: Many AI generators (including Google’s Lyria and Veo) use SynthID, an invisible digital watermark embedded in the pixels that only another AI can see, ensuring we can always tell what is “real” and what is “generated.”
FAQ SECTION
1. Is AI art copyrightable? In many jurisdictions (including the US), the law currently states that AI-generated content without “significant human creative input” cannot be copyrighted because copyright requires a human author.
2. Why does AI struggle with text in images? Because the AI doesn’t “read.” It sees letters as shapes. It knows that the shape “E” often follows “H” and “E” in the word “HELLO,” but it often gets the spacing or the number of letters wrong because it’s just guessing the “visual probability” of the shapes.
3. What is a “Seed” in AI generation? A seed is a number that determines the starting pattern of the random noise. If you use the same seed and the same prompt twice, you will get the exact same image.
4. Can I use AI image generators for free? Yes. Tools like Bing Image Creator (DALL-E 3) and certain versions of Stable Diffusion are free to use. Midjourney requires a paid subscription.
5. What is “Prompt Engineering”? It is the art of figuring out which specific words (like “octane render,” “hyper-realistic,” or “volumetric lighting”) trigger the AI to look in the highest-quality parts of its Latent Space.
6. Does AI art “steal” from artists? This is a major debate. While the AI doesn’t “copy” work, it was trained on artists’ styles. Many artists argue that this “style theft” devalues their human labor.
7. Why are some prompts “blocked”? To prevent the creation of “Deepfakes,” CSAM, or violent imagery, companies use “Safety Filters” that scan your text and the final image for prohibited patterns.
8. How long does it take to train an AI model? Large models like Stable Diffusion 3 take months of training on thousands of high-end GPUs (H100s), costing millions of dollars in electricity and hardware.
9. Can AI create images from my brainwaves? Experiments have shown that scientists can use fMRI scans of a human brain while they look at a photo and feed that “neural noise” into a Diffusion model to reconstruct a rough version of what the person is seeing. It’s early, but it’s possible!
10. What is “Negative Prompting”? It’s telling the AI what you don’t want. By typing “extra fingers, blurry, low quality” in a negative prompt, you are telling the AI to move away from those mathematical coordinates in Latent Space.
OTHER USEFUL BLOG SUGGESTIONS
- How Recommendation Algorithms Work: The Science of Your Feed
- How Does ChatGPT Work? The Simple Science of AI Answers
CONCLUSION
The blinking cursor in the text box is the modern-day equivalent of a wizard’s wand.
When you use an AI image generator, you aren’t just “filtering” the internet. You are navigating a mathematical representation of the entire human visual experience. You are reaching into a universe of trillions of possible images and pulling one and only one into reality.
The technology isn’t perfect. It still hallucinates extra limbs, and it still doesn’t understand the physical gravity of a scene. But it is learning. Every time you “thumbs up” an image, the model gets a tiny bit better at understanding the difference between noise and art.
We are entering an era where the only limit to what we can see is what we can imagine. Whether you are a student using AI to visualize history, or a professional designer using it to brainstorm, the ghost in the machine is here to stay.
The “fog” is lifting. What are you going to create next?